
Updates - S - Data Engineering Brings In Paradigm Shift To The Security Industry (1/3)
We continue to like SentinelOne as one of the most attractive opportunities in the cybersecurity industry.

Executive Summary
XDR is one of the most important & fastest growing areas of cybersecurity though its currently being held back because of data management headwinds.
S has made great strides in solving this by acquiring/integrating Scalyr, a disruptive log management vendor that can deliver multiple times better cost/performance.
The Scalyr integration gives S the opportunity to extend its lead in the XDR space – better organized data means better AI/ML models and better security.
The recent Attivo acquisition compliments S’ XDR platform with Zero Trust capabilities.
Relatively speaking S looks undervalued vs other stellar high growth names. The DCF valuation also indicates substantial upside.

Contents
XDR & Scalyr technology (1/3)
Scalyr vs. Humio; RSO, STAR, and DataSet; Attivo (2/3)
Financial Analysis & Valuation (3/3)
XDR Needs Quick Access to Quality Big Data
There have been several evolutions in the endpoint security market during the past 30 years. The market started out with signatured-based AV >>> then signatured-based AV with firewall tweaks >>> then app whitelisting and sandboxing >>> then cloud-based EDR (Endpoint Detection & Response) >>> then EPP with static AI AV >>> and the latest trend is XDR (Extended Detection & Response). See our initial SentinelOne report for more detailed history of the AV industry.
EDR consists of collating telemetry from endpoint agents into the cloud for large scale analysis of the global threat landscape and malware/suspicious behaviour detected on individual endpoints can be contained, investigated, and deleted remotely from the cloud. XDR expands the sources of telemetry to include information from multiple systems (network logs, SIEM systems, and any other point solution) that can provide useful context for detecting threats and protecting endpoints, and applies more advanced analytics for correlating alerts – which translates to richer insights and reduced alert fatigue for analysts.
This huge volume of data from an extensive array of sources needs to be brought into a single data lake so that the XDR platform can interact with it and deliver value via deeper context enrichment. There are various players with their roots in log management that are attempting to mold their SIEM (Security Incident & Event Management) system to achieve this level of data aggregation for the XDR market, though such endeavours are not proving highly effective. SIEMs were originally designed for general log management to facilitate the adherence to compliance requirements, and over the years they were modified to also cater for security needs. Though, SIEMs are still too generic in nature to provide high value for security use cases. It takes a lot of experience and expertise to apply a SIEM to deliver meaningful threat information for analysts to swiftly respond to.
Furthermore, due to the size and indexed nature of the SIEM’s log management system, it typically takes a long time for analysts to query and retrieve data. And generally, it takes analysts several days or even weeks to fully triage alerts and complete an investigation and response, in large part because of the voluminous false positive alerts. The TL;DR is that XDR requires a security-focused data lake, though the incumbent solutions are too generic and inefficient, and require too much work and expertise to make them highly effective for protecting an org from threats.
The Scalyr Acquisition
In Feb-21, S acquired Scalyr for $155m to provide a more efficient log management back-end in which to leverage their AI-powered XDR platform. This was a large acquisition taking into account S’ revenue level (TTM revenue was $93m at the time of the deal) but a very differentiated move considering all other next-gen vendors (except CRWD – more on this later) are still using legacy SIEM solutions to feed their platform.
Scalyr’s data lake enables super-fast ingestion, querying, and retrieval of data – 96% of all queries are complete in under 1 second, many of which are completed in a few milliseconds. This is a huge step-up in speed vs the competition and will serve S’ core strategy of delivering more effective security with better AI.
Big data >>> better organized >>> faster ingestion + faster retrieval >>> faster flow of high-quality data >>> better AI/ML models >>> more effective security defenses.
Figure 1 - XDR Needs Better Data
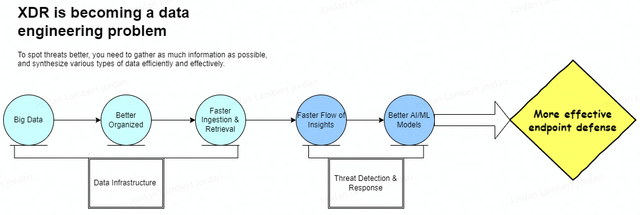
Source: Convequity
A Little Dive into the Issues with Handling Big Data
Traditionally databases have been designed with a rigid index-based schema that describes every element, including tables, rows, columns, indexes, and relationships, and any data that is undefined is discarded. This prevents the capture of low-quality, incomplete, or malformed data, but the downsides are that such databases require a lot of up-front formatting, the dealing with various constraints, an abundance of maintenance, it is inflexible to new data types, and needs to sacrifice a lot of undefined raw data that actually holds a lot of potential value.
Furthermore, searching and retrieving data across an index-based database is slow, and may take several hours for a large dataset. And this inefficiency results in placing a huge load on the CPU, thus driving up significant costs for businesses. The efficiency of index-based databases is inversely correlated with a number of variables, though the file sizes (average and size of the biggest files), the frequency of updates, and the number of people the files are shared with or accessible by, are some of the primary factors that slow them down and consume a lot of CPU resource.
Figure 2 - Factors Adding Significant Load to the CPU and Slowing Down Data Ingestion/Retrieval
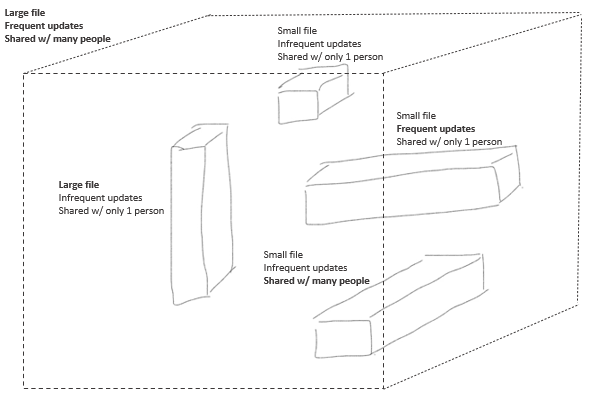
Source: Inspired from Scalyr presentation, Convequity modifications
So, index schema databases have their advantages – useful for smaller and structured datasets, but for larger and unstructured datasets, they are slow and lose a lot of context that can be accrued from the discarded raw data. Additionally, they are good for searching for the top 10 [whatever] matching a keyword but such searches are not executed in the realm of observability – which is the primary purpose for log management. Therefore, applying index schemas to the needs of an XDR platform is not going to generate the quality of alerts and insights necessary to improve an org’s security defenses.
Historically, the slow speed of index schemas hasn’t been too much of a concern for end users just concerned with business analytics – many have just accepted the slowness and plan their time management accordingly. However, more speed is becoming increasingly demanded to respond to security threats faster, and because business success in general is becoming predicated on near real-time responses to market dynamics.
Schema-less, aka NoSQL, databases are an innovation to better manage big data sets. They can store, query, and retrieve any data type which makes them capable of adapting as a company’s data-driven demands change. And every piece of information is stored in a JSON-style (JavaScript Object Notation – pervasively used for transmitting data) document which can have varying sets of fields, with each field able to store different data types, as shown in the snippet below.
Figure 3 – Simple Example of Unstructured Data

As each piece of data is stored within a JSON-style document, it is kept in its raw form meaning every detail is available – nothing has been stripped away to match a schema – which is great for analysts looking to manipulate big data sets and gain richer insights.
And the other benefit is the increase in speed. As enterprises adopt more IaaS they are increasing their use of microservices architectures, meaning data generation is expanding in breadth and depth (breadth because the hosting of a single application is divided and sprawled across multiple server clusters and each application component uses a variety of APIs to connect with external services, and depth because of the layers of abstraction throughout the hardware/software stack: physical servers > OS > containers > runtimes > k8s > databases > services/APIs > applications). In essence, the greater use of IaaS is resulting in pretty much all datasets becoming very large and hence not well suited to index schemas. By removing the index schema, NoSQL databases allow for more efficient search and retrieval.
Why is Scalyr So Revolutionary?
There are many players in the NoSQL database and log management market, so what makes Scalyr so unique? Well, there isn’t one feature that makes Scalyr’s data lakes lightning fast – rather the speed and scalability are results of a thoughtfully crafted architecture that takes the best parts of modern database innovation and combines them with a novel and proprietary way of ingesting data and executing queries. We’ll touch on the main components.
Scalyr’s agent and parsing engine parses the logs from the data sources to extract structured fields and places them in a NoSQL columnar database (either cache or storage). Columnar databases are not unique to Scalyr but they facilitate faster search and retrieval than databases that search row by row. For example, say the height, weight, age, and other bodily characteristics are the columns and the person names are the rows - with a columnar database the search can retrieve all the heights by selecting all the height column, whereas as traditional databases would search through each row to find each height. So, columnar formats are more conducive for big data analytics whereas traditional row-first databases are more suited for transactions (will need all the identifiers – ID, payment amount, date, location, etc. - of each person involved in a transaction).
Figure 4 - Scalyr's Architecture
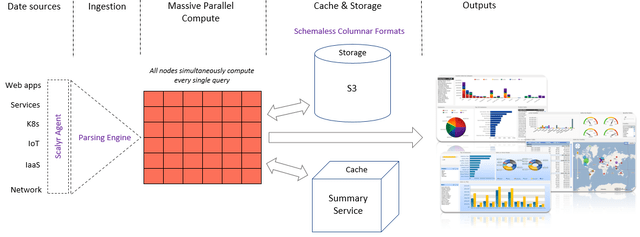
Source: Inspired from Scalyr presentation, Convequity modifications
As can be seen above, similarly to Snowflake, Scalyr has separated the compute layer from the cache and storage – our Superclouds: Part 1 article goes into detail as to how Snowflake has architected this. The same type of architecture enables Scalyr to deliver that elastic scale for customers.
The real pioneering aspect of Scalyr’s operation – the truly novel part – is that every single query is simultaneously processed by every node of a cluster. This is in stark contrast to what other big data vendors are doing, which is to have each node process individual queries simultaneously. Scalyr’s massively scaled compute parallelism – whereby every CPU core within a node cluster commits to the query - results in 96% of all queries being completed (from query to data retrieval) in under 1 second and then the node cluster is ready to process the next query.
Scalyr’s Summary Service is also a novel piece of engineering. It serves as a cache for repetitive queries so that the data can be retrieved super-quick with minimal processing. They claim that c. 90% of analyst queries are common enough to be handled by the Summary Service, meaning that the massively parallelizable compute engine is mostly available for the 10% of ad-hoc, exploratory queries – thus offering very high resource availability. This architecture can process data at Petabytes of scale and has already enabled S to build pioneering solutions for helping SOC analysts utilize.
We’ve done our best to articulate the potential of integrating the Scalyr architecture into S’ back-end infrastructure, though, the initial press release on the acquisition probably explains it the best – or at least is complimentary to what we’ve discussed thus far.
With this acquisition, SentinelOne will be able to ingest, correlate, search, and action data from any source, delivering the industry’s most advanced integrated XDR platform for real time threat mitigation across the enterprise and cloud.
According to Gartner, “building an effective XDR is more challenging than it might seem. Lack of data collection, common data formats and APIs, as well as products built on legacy database structures, make it difficult to integrate security tools even within the same vendor’s product portfolio.”
Born in the cloud, Scalyr’s SaaS platform unlocks the full promise of XDR. By eliminating data schema requirements from the ingestion process and index limitations from querying, Scalyr can ingest massive amounts of machine and application data in real time, enabling organizations to analyze, query, and action data with unparalleled speeds and cost-effectiveness. This provides SentinelOne customers with autonomous, real time, and index-free threat analysis and mitigation beyond the endpoint – across the entire enterprise and cloud attack surface – something not possible with today’s human powered and schema-constrained cybersecurity products.
“Through our acquisition of Scalyr, SentinelOne is solving one of the industry’s biggest data challenges for delivering fully integrated XDR capabilities. Scalyr’s big data technology is perfect for the use cases of XDR, ingesting terabytes of data across multiple systems and correlating it at machine speed so security professionals have actionable intelligence to autonomously detect, respond, and mitigate threats,” said Tomer Weingarten, Co-Founder and CEO, SentinelOne. “This is a dramatic leap forward for our industry – while other next-gen products are entirely reliant on SIEM integrations or OEMs for point in time data correlation and response, SentinelOne uniquely provides customers with proactive operational insights from a security-first perspective. The combination of Scalyr’s data analytics with our industry leading AI capabilities ushers in a new era of machine-speed prevention, detection, and response to attacks across the enterprise.”
Scalyr broadens the aperture of data sources, creating a real time data lake for ingesting structured and unstructured data from any technology product or platform – including Microsoft, AWS, Google, CrowdStrike, and more – as well as internal enterprise data sources. Diverse XDR data, coupled with SentinelOne’s AI-powered Storyline technology, automatically connects disparate data into rich stories and autonomously identifies malicious behaviors, especially techniques exhibited by advanced persistent threats – including APT malware like Sunburst.
S's PR release on this acquisition was jam-packed with information. Firstly, it is about the challenges associated with building the XDR platform. XDR requires a different skillset relative to EPP and EDR in that the data infrastructure backend is the underlying core competitive edge. Put simply, cybersecurity is a data problem if you want to leverage more automation and AI to improve defenses.
As both Gartner and Forrester have alluded to, building a real XDR platform is very hard. Cybersecurity and enterprise software in general are getting more and more fragmented, with 40+ year-old COBOL applications running together with the latest cloud-native apps. This means that they have vastly different APIs and data formats that make it super-challenging to bring in data altogether in an efficient and effective way.
Furthermore, data ingesting is just the beginning. You need a powerful back-end to integrate with various security tools seamlessly. This back-end should be able to save data and read/query data with high availability, performance, and cost-effectiveness. Legacy solutions, or solutions that have not seen major revamp after the launch, will gradually get smoothed out.
Investors might also find it interesting to consider how Storyline, mentioned in S’ managements remarks above, interacts with Scalyr (now renamed as DataSet – more on this later) to improve one another. Storyline helps SOC analysts and MSSPs/IR (Managed Security Service Providers & Incident Response Units) connect the most pertinent events so they can see the series of actions a bad actor has taken, and avoid getting bogged down in voluminous disjointed alerts (many of which will be false positives). In essence, Storyline provides context enrichment for more quicker triaging, and as we’ve depicted below, Storyline can feed back context-enriched data to DataSet, so that DataSet can refine itself and deliver even more context and faster speeds to Storyline.
Figure 5 - The Interaction of Storyline and Scalyr (which has been renamed to DataSet)
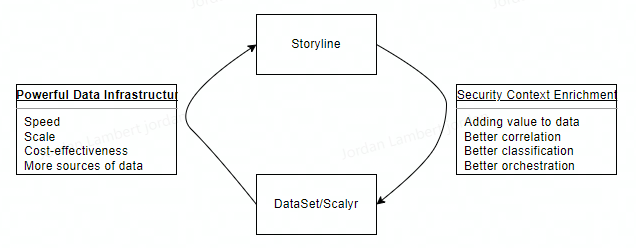
Source: Convequity
SentinelOne-Scalyr vs Crowdstrike-Humio
Crowdstrike (CRWD) acquired Humio, another pioneering log management vendor, at around the same time S acquired Scalyr. Whereas Scalyr’s biggest innovation comes from the massively scaled parallelizable compute, Humio’s innovation comes from techniques that radically reduce the scope of a data queried and retrieved. By narrowing the scope, queries can receive the required data much faster compared to index-based alternatives.
As depicted in the diagram below, Humio first reduces the amount of data by dividing the logs into time windows, which drops the amount of data to be queried by 100x – from 1 Petabyte to 10 Terabytes. Then, Humio delivers another 100x reduction by tagging logs so that if an analyst only needs logs from cloud instances and not on-prem, they can specify this and reduce the amount of data queried and retrieved. A further 100x reduction is achieved by applying bloom filters which omit logs that are not important in the search – for instance, an analyst wants to query the number of daily app authentications in the U.S. only, hence the bloom filters would remove the logs associated with the rest of the world. Lastly, an additional 10x of data is saved by compressing the data in cache and storage.
Figure 6 - Humio's Techniques to Radically Reduce the Amount of Data Queried and Retrieved
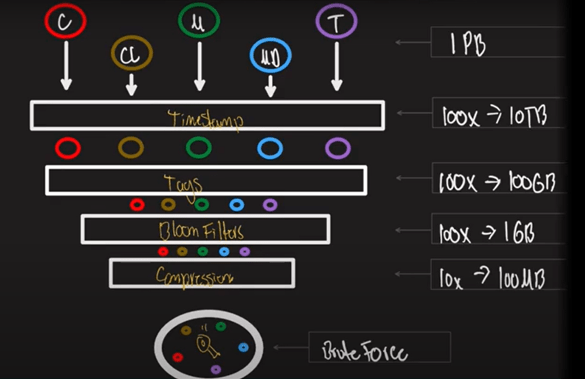
Source: Understanding Humio in 10-Minutes...Or So (Part 2)
Collectively, these engineering techniques enables Humio to dramatically reduce the amount of data queried by 10,000,000x. And it’s probably needless to say, but Humio also utilizes the schema-less and columnar formats to enhance the speed of ingestion and querying.
While Humio is impressive, we think the technology is less disruptive than Scalyr’s. We would say the latter’s is more novel and harder to imitate because the brunt of the innovation is at the hardware level (or an abstraction at the hardware level). And this inference can probably be supported by Scalyr handling data at PBs per second whereas Humio is currently processing data at a max of 1 PB per second – still very impressive though.
Humio is a direct competitor to Splunk (we’re going to follow-up this report with an analysis of Splunk’s challenges) which explains why CRWD decided to put in an offer for Humio. Early on CRWD chose SPLK for its SIEM requirements because it was the BoB at the time. Though, as we’ll cover in detail in a follow-up report, SPLK has really struggled to transition its platform to deliver SaaS and deliver cloud scale performance – and this has been the case for all legacy on-prem log management vendors because such a transition is an incredibly complex thing to manage.
Whereas S has chosen a path not dissimilar to PLTR – a contrarian and long-sighted strategy for building the company’s architecture - CRWD got started with the typical DevOps mindset whereby you produce a minimal viable product and quickly launch it and get quick feedback from the market. The preference for quick GTM over product perfection is often the better strategy – just think of NET vs FSLY. But sometimes product perfection is the more fruitful strategy, given the company can withstand the slower growth in the early days (e.g., PLTR). The jury is still out, so to speak, as to which out of S’ and CRWD’s will be the better approach in the long-term. Of course, CRWD has reached $1.5bn in TTM revenue, grabbed a large market, is still sustaining hyper-growth, has solid FCF margin, and is close to GAAP profitability. Though, the big drawback of this rapid ascent and obsession with growth right from the onset is that CRWD undoubtedly has greater technical debt than S.
A major part of this technical debt for CRWD is/was attributed to using SPLK – a log vendor in the process of being legacy-fied. CRWD initially went with SPLK for a faster GTM – this allowed CRWD to focus on the threat telemetry collated from the endpoints which could be stored and later queried in SPLK’s SIEM, and also to focus on the human-driven incident forensics, which is the actual background of the founder, George Kurtz. But SPLK’s technical debt was a major headwind for CRWD’s ambitions to scale and ingest more disparate data sources for their XDR endeavours. In early 2021, CRWD decided to buy Humio because of its similarities with SPLK, mainly being it operates on a software license to customers. Humio can be installed on-prem and in the cloud but works with customers on a license arrangement, it isn’t a cloud-native SaaS solution. So, you can infer why CRWD chose Humio over a SaaS solution like Scalyr – being similar to SPLK, the integration would be quicker and hence less operational disruption and speedier contributions to growth. Also, Humio is a more mature vendor with a more established GTM – perfect for CRWD’s apparent obsession with growth before anything else.
On the contrary, S’ play for Scalyr is less short-term oriented and more long-term visionary – a riskier and more challenging acquisition but potentially much more fruitful. Scalyr is a younger innovator in log management space, and as S mentioned, Scalyr has a very thoughtful technology leader (former engineer that created Google Drive, in which his challenges inspired him to found Scalyr) and its design is very novel. Instead of using the traditional 'index' technique to ingest data, Scalyr boosts the ingestion process by directly pushing the data to the pipeline. With various tweaks, Scalyr is able to deliver a more performant and cheaper log management solution.
To us, both Humio and Scalyr are great acquisitions for CRWD and S. Humio is clearly a better fit to CRWD because its product line is more similar to SPLK with on-prem hosted software available that could directly replace existing SPLK implementations without much need for a big revamp, and Humio’s higher revenue helps CRWD sustain its growth. On the core technology, however, it seems that Humio’s solution is less disruptive compared to what Scalyr is doing. In contrast, both S and Scalyr are earlier on in their company maturity and hence S can afford to do a bigger revamp and radically improve its back-end data infrastructure, whereas CRWD has opted for an evolutionary improvement.